Covariate Search vs. Semantic Search: which one performs better?
Michelangiolo Mazzeschi • 2024-12-26
In-depth comparison between Covariate Search and Semantic Search, is Covariate Search better?

Covariate Search vs. Semantic Search: which one performs better?
In this article, I am going to compare the performance between these two kind of searches, showcasing why covariate search is able to outperform semantic search when applied to sets of keywords. Covariate search has been built for this very purpose, so it is natural that it can significantly outperform text-based algorithms, but I will also try to explain the reason behind this improvement.
A quick refresher on Covariate Search
If you have not understood what covariate search is and how it differs from semantic search, you can read this article. In a few words, while semantic search can only process a single piece of information (like a piece of text), covariate search is able to process groups of information (groups of keywords), allowing this algorithm to perform much better when searching for groups of keywords semantically.
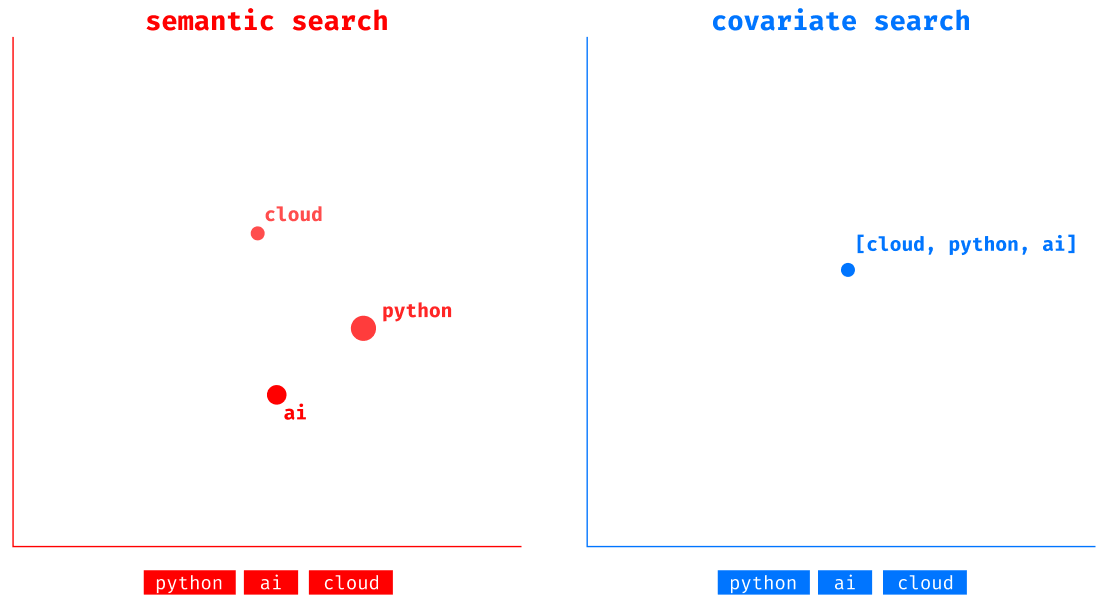
Can Semantic Search be used on keywords?
There is, however, one very smart trick that can be used to extend semantic search to the domain of (semantic) keyword search, which is converting a set of keywords into a string. This “workaround” works well enough, but has several technical flows that are easily recognizable. Most importantly, we need to address two major flaws that are inherited by all semantic models:
- Lack of Consistency
- Narrow Recall
To showcase these flaws I will use the tech resume database as a benchmark. This database, consisting of the tech-related skills of 18.000 resumes, has been prepared to run both semantic search and covariate search so that we can easily grasp the difference between the two models in action. The text encoder that has been used is all-MiniLM-L6-v2, which is, by far, the most common text similarity model used on the web (78M downloads).
***the speed required to assign each score makes this demo MUCH SLOWER, and cannot be compared with the standard covariate search speed).
Consistency
Consistency is the biggest flow of any semantic search model, and, unfortunately, there is no way to solve it, as it is caused by the self-attention mechanism that governs the transformer architecture. The order of keywords
Covariate search consistency will always remain at 100% (the order of keywords does not change its results because all inputs are initially one_hot encoded).
However, by simply changing the order of keywords in semantic search we get completely different results. This is a very challenging problem in retrieval methods because it makes the model unreliable. Let us look at a very simple example: this is what happens on semantic search if we use the word programming in the first position (left) vs. the last position (right). The results change drastically (they only match at 71% - 2 results are not in both searches).

Semantic Search Consistency only reaches 30%!!!
There are many possible ways to estimate the consistency score of a semantic model. The easiest is to check which are the search results that, when switching keywords several times, remain in the top n results (7) for each similar search. Semantic search is not consistent at all (as shown, just changing the position of a single keyword in the query leads to drastic changes in retrieval).
Narrow Recall
This phenomenon does not have a proper name yet, but it is the Achilees heel of all semantic models, and it is obviously prevalent in keyword search. The problem can be described as such: even if our query contains multiple elements, the model can easily retrieve samples with an abundant proportion of some of the elements, but not necessarily all of them.
For example, the following query counts 7 input keywords, but the results only contain 2 out of 7. The result is still valid, but we are aiming to maximize this score and find candidates that have most of the outlined requirements in the input query.
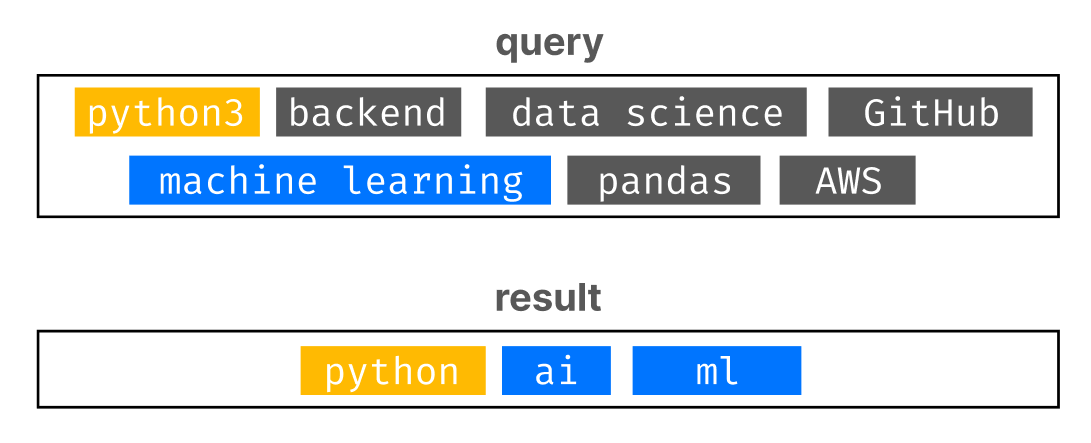
How can we measure the difference between covariate search and semantic search? A very simple, yet effective, method is to check whether each result (found in a different row, for a maximum of 7 rows) has maximum recall.
***the speed required to assign each score makes this demo MUCH SLOWER, and cannot be compared with the standard covariate search speed).
If both keywords from the query have been found in the results (we can inefficiently use semantic search for the only purpose of score validation), we can give a maximum score of 1, otherwise, the score is equivalent to the proportion of keywords found compared to the query (ex. if our query contains 5 keywords, but our result only counts 2, the final score will be 0.4).
query: SQL, javascript
The following example shows what happens when we search for two keywords: SQL and javascript.
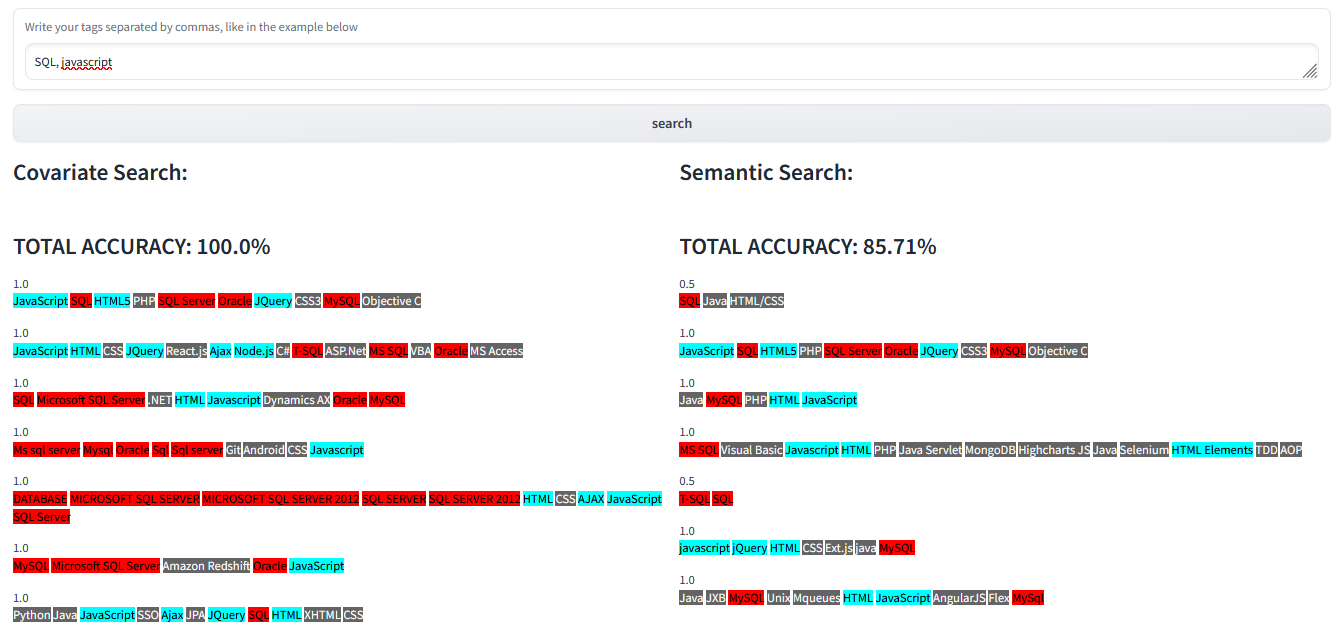
While in this example covariate search has found results with all matching keywords from the query, semantic search shows several examples of narrow recall (result #1 and result #5).
query: python3, management, customer care, SQL, selling
The following example shows what happens when we search for a more complex query.
What about more complex queries? The more we add keywords, the more we can expect the overall accuracy to diminish (if we use the query keywords as a benchmark). For example, if we were to search for 100 keywords at once, I doubt we would find any resume containing all of them (making perfect accuracy impossible).
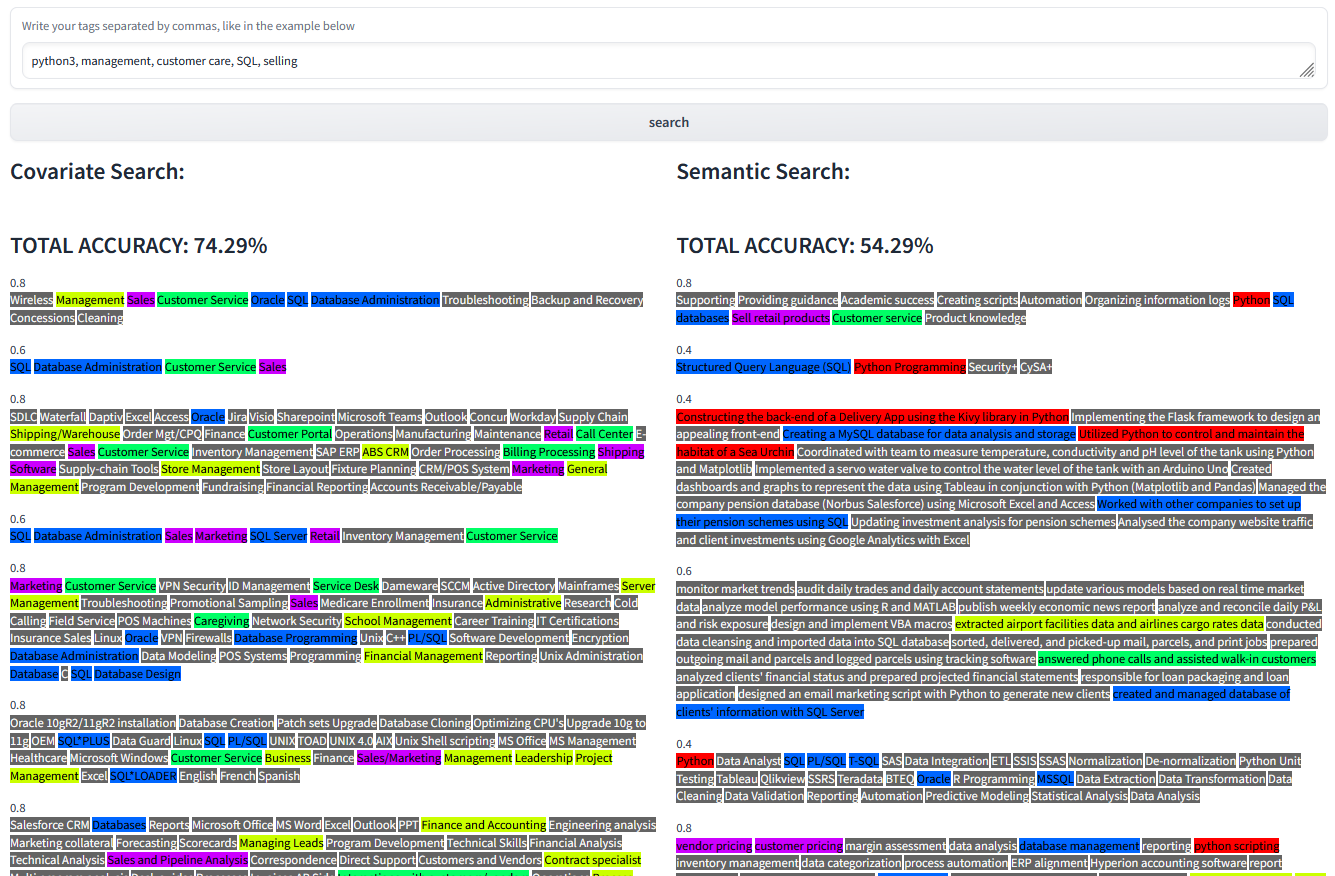
More examples of narrow recall can be seen when running semantic search (result #2, result #3, and result #5).
query: database, python, sales, rust, C, SQL, javascript, programming
Let us try with an even more complex query:
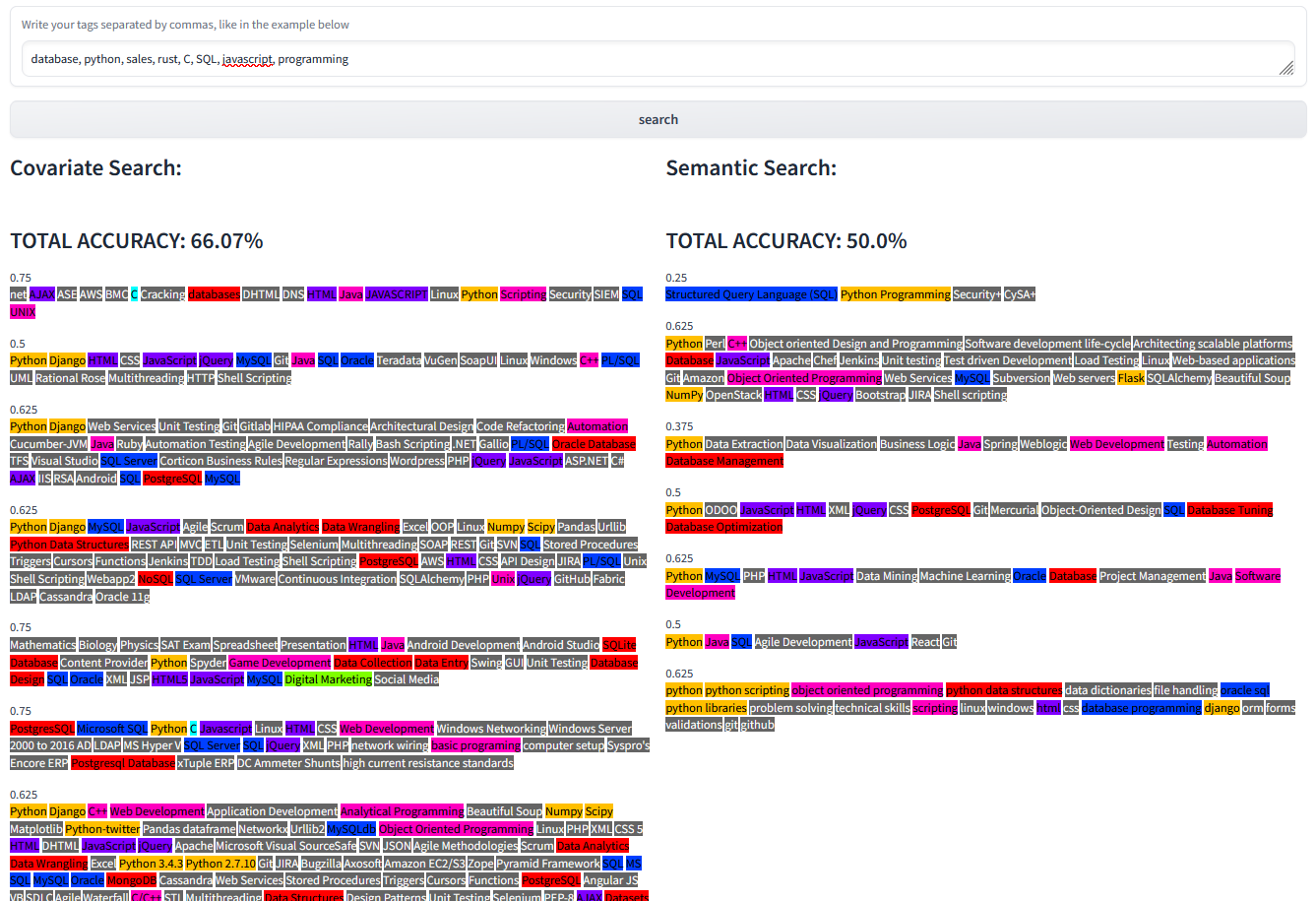
However, in this case, results are slightly more consistent result #1 is ignoring most of the input keywords.
How does semantic search and covariate search compare?
To find out what is the actual performance difference between the two searches, I have employed a batch of Monte Carlo simulations. I tested the search by inputting from 2 to 25 keywords and running 400 random searches (picking different keywords from the pool each time). The overall performance of both semantic search and covariate search are outlined in the following chart:
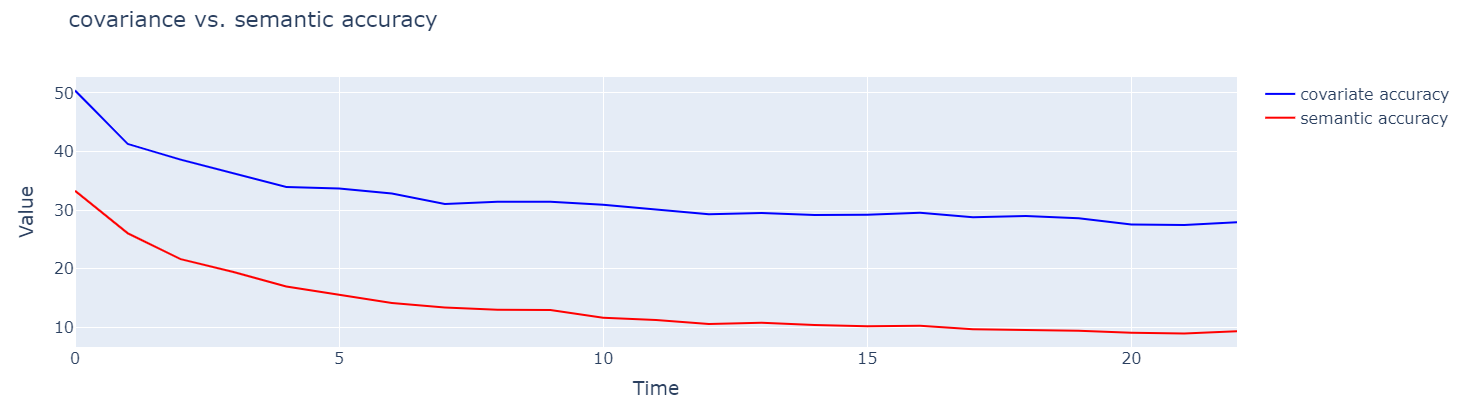
Covariate Search shows almost a 20% improvement consistently
The results are quite impressive. Especially for any search with over 5 keywords in the same query:
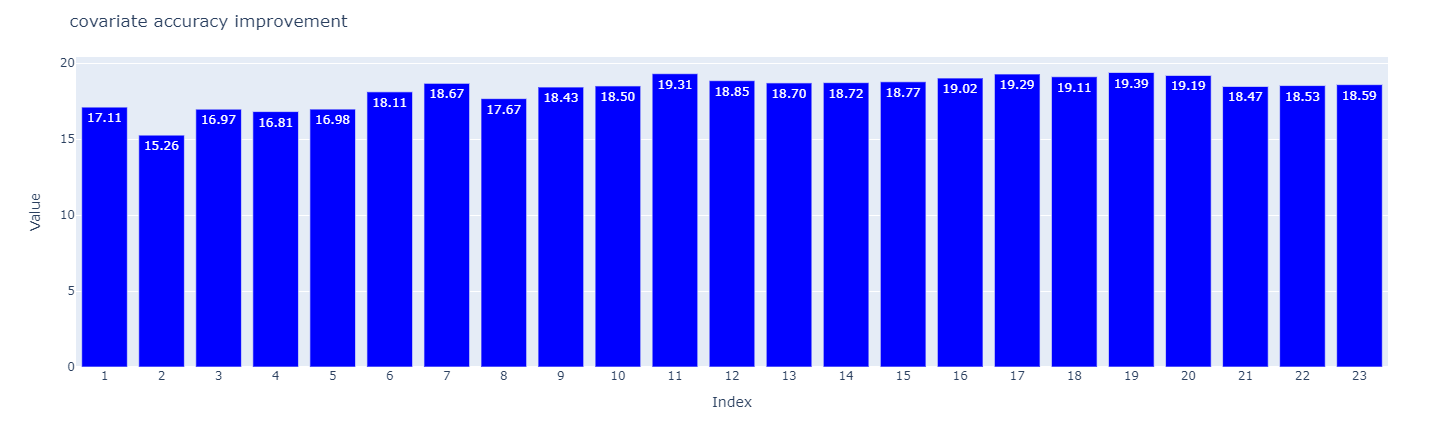
In some cases (about 1/8), the performance difference has even reached 40%!
What about other models?
Do other models behave differently? all-MiniLM-L6-v2 is a very popular model, but, despite its advantages (speed and accuracy), may be considered outdated by some hardcore readers. To be fair with our comparison, let us use jina-embeddings-v2-base-en, a much more popular choice for RAG (and that has been released this year).
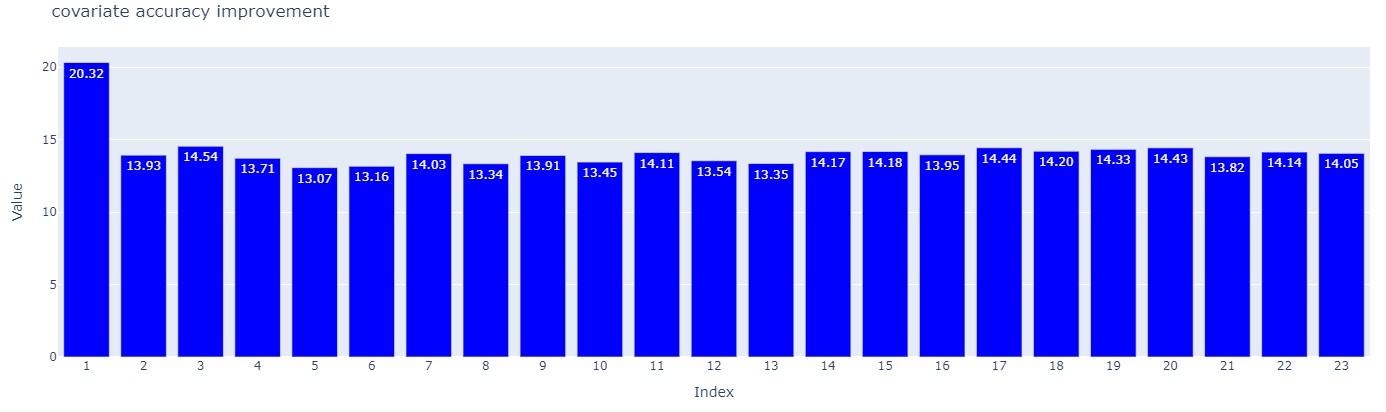
Though we can notice some minor improvements, covariate search still holds an edge with a consistent 14% improvement over semantic search. We need to be aware that more performing models (such as jina-embeddings-v2-base-en require much more RAM and computing power, to be precise 5x the RAM requirements of all-MiniLM-L6-v2 for just a 5% improvement, making it very inefficient for some use cases).
Conclusion
Covariate Search, when used to search on keywords, has the advantage of having a perfect consistency score (100%). In addition, when matching keywords suffers less of narrow recall because it tries to find samples that match all keywords at the same time. This has monumental implications for the way we search for sets of elements, especially when searching for resumes.
See More Posts
Cardy
Copyright © 2021 Govest, Inc. All rights reserved.