Replacing Metadata Filters with Weighted Semantic Search
Michelangiolo Mazzeschi • 2025-01-04
replacing-metadata-filters-with-weighted-semantic-search
In the past articles, we have introduced the search capabilities of covariate search. The core technology is able to transfer semantic relationships to a regular one_hot vector. This approach results in a series of advancements, including speed, consistency, and accuracy. However, the most underrated potential derived from covariate search is weighted search, an algorithm that semantic search does not yet support.
A regular search problem
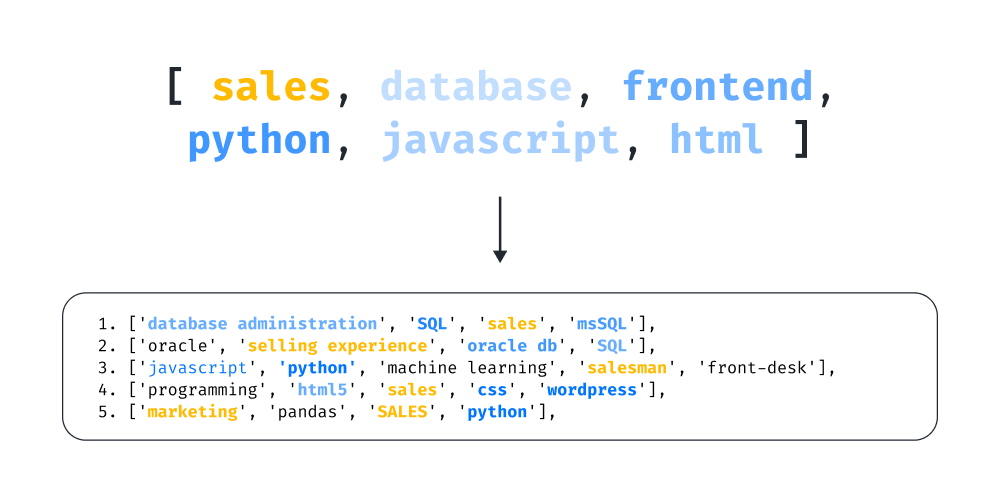
To showcase the potential of weighted semantic search, let us begin by describing a very common problem. Imagine we are searching through thousands of resumes, and we want to find all the salesmen who have experience in a specifc technology (common technologies such as database, SQL, python, frontend, wordpress…). The first approach that comes to mind is to use all the keywords in the same query.
However, as we can clearly see from the results (feel free to try the search by yourself on this link), neither semantic search or covariate search can find the desired profile:
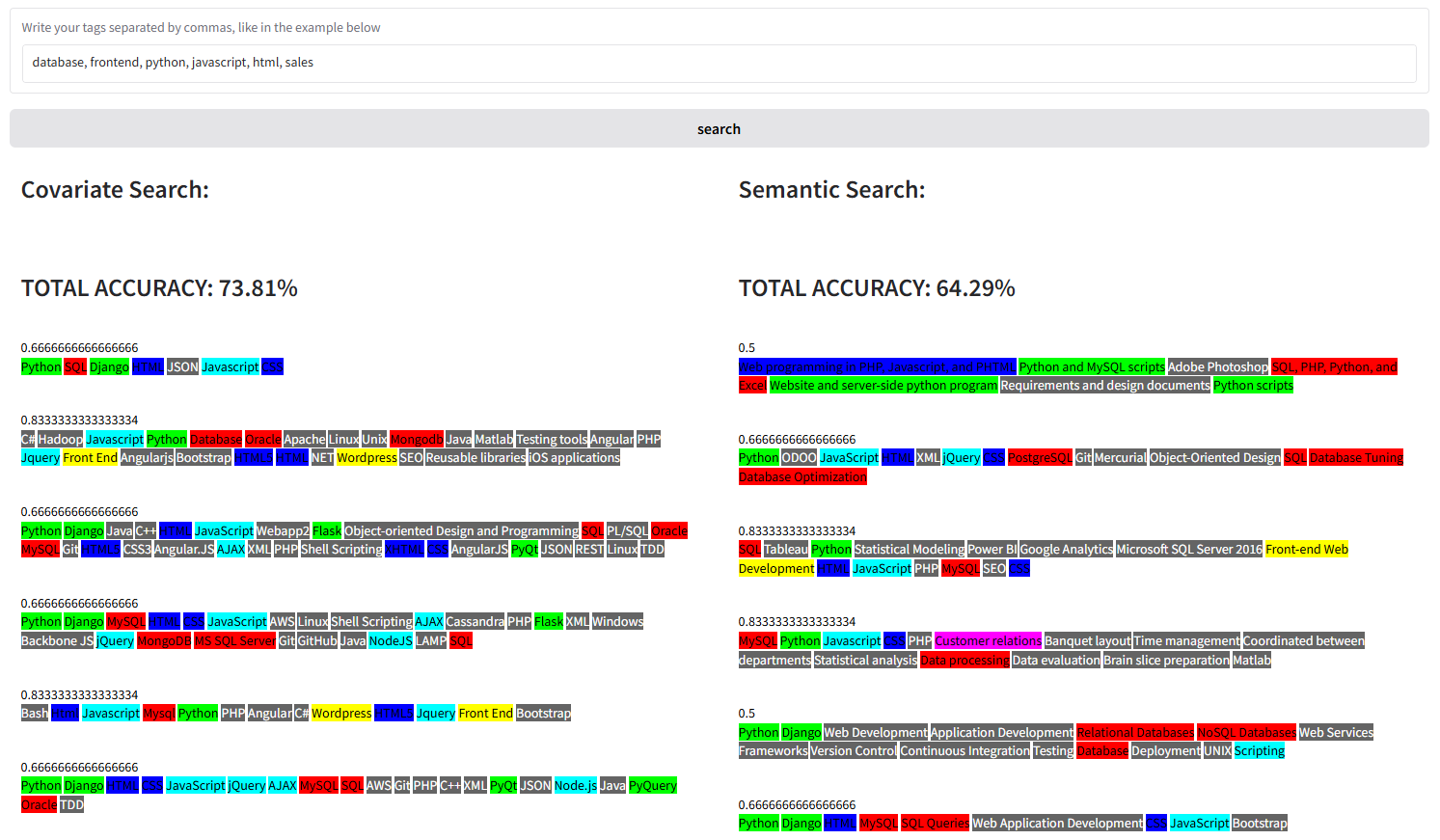
What is going on? Both algorithms in their raw state try to maximize the number of relevant keywords found in each resume. Because the keyword sales is different from all the others in the query, it is much easier to find a match that contains, for example, related keywords like frontend and javascript, assigning much less weight to sales. As we can see, none of the current search algorithms are a solution, when used on unsupervised data.
Modern problems require modern solutions
When any unsupervised approach fails, it is still possible to obtain the desired results by tweaking and preparing the data.
Metadata filters
The most common solution to this problem is to use metadata filtering: the assignment of a second layer of labels that can be used to filter our desired population. In our case, we are only interested in salesmen, hence we will need to use that as our prime label.

The main problem with this approach is that requires supervision (not necessarily by a human), which means that more resources need to be employed to prepare the data for multi-layer filtering.

The objective of machine learning is to solve a problem using a completely unsupervised approach. Can we find a smarter solution to this problem?
Why can’t Semantic Search support Weighted Search?
Why can’t semantic search support weights? When we use semantic search to encode information, we can only encode one element at a time. In the case of a set of keywords, we need to convert it into a string and then encode it. There is no proper (mathematical) way or best practice that lets us assign a higher value to a keyword versus another one, outlining one of the biggest limitations of semantic search.
Assigning weights to Covariate Search
By default, when enabling covariate search, we start with a one_hot vector: each keyword in our query is assigned a value of 1. Then, we transfer the relationships to this vector using a dot product of all the keyword relationships (you can read the process in detail in this article).
However, instead of using 1 as a default value, we can freely alter the weights. For example, we could assign a higher value to sales compared to all the other keywords:
{ "sales" : 0.4, "database" : 0.12, "frontend" : 0.12, "python" : 0.12, "javascript" : 0.12, "html", 0.12}The following image shows the results obtained from this query, to be honest, they look phenomenal: by employing a completely unsupervised approach, we have been able to emulate the capabilities of metadata filtering without touching the data beforehand. All the following profiles belong to salesmen who work in the tech space.
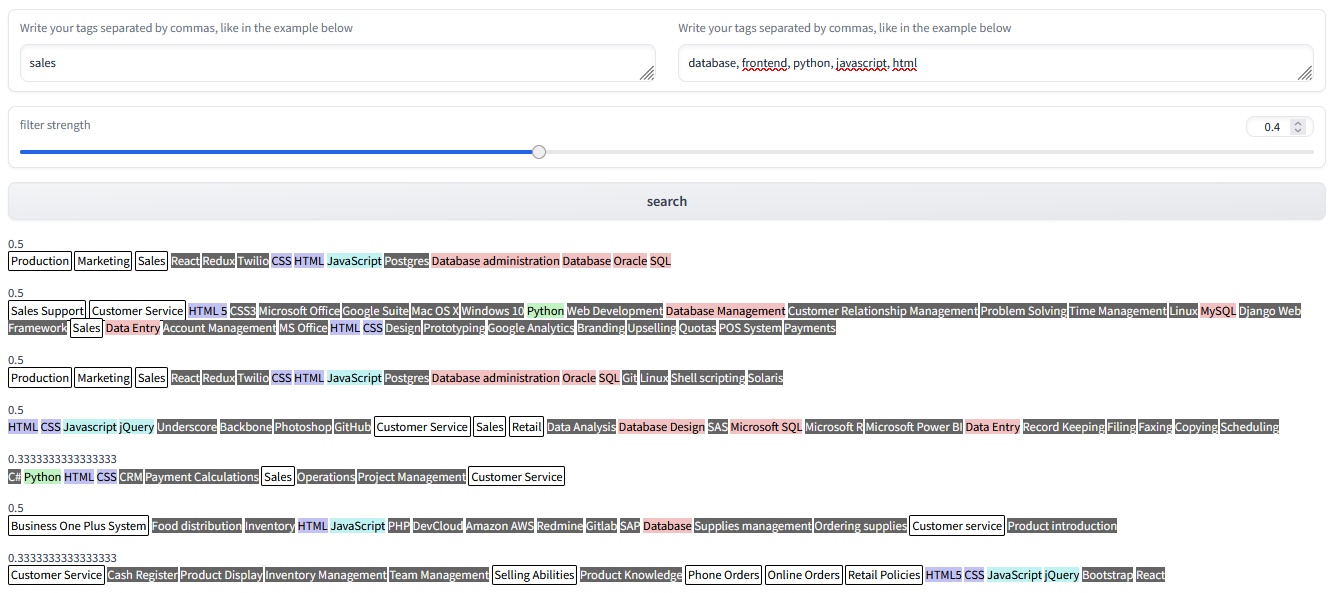
You can try weighted semantic search at this link.
Two-layer approach
One very effective way of using Weighted Semantic Search (mostly for practical purposes) is using our two-layer approach. We only use two sets of keywords, but we assign a whole score to each set. In the example above, layer1 has a total weight of 0.4, while layer2 has a total weight of 0.6. The weight is then equally distributed among the keywords of each set.
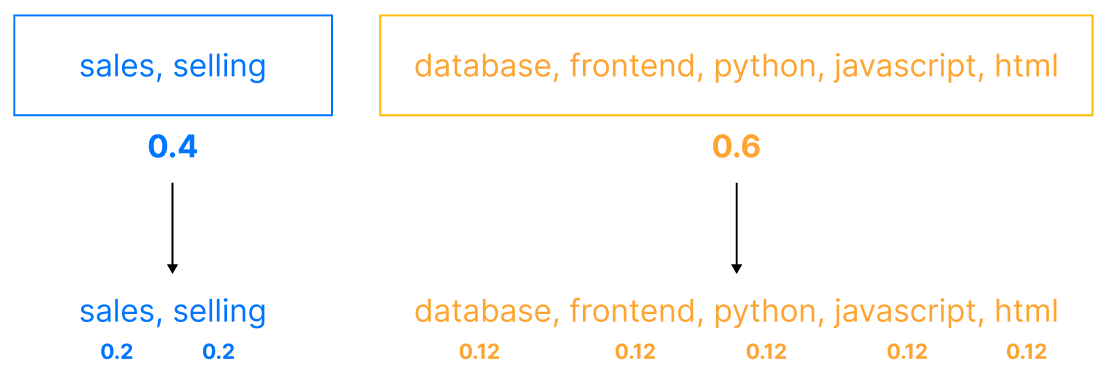
When searching for information manually, this approach can be used without excessively complicating the query for the end user and retaining the user-friendly aspect of advanced queries.
Conclusion
Weighted Semantic Search should open the door to new search approaches, and, with time, it will gradually replace the practice of metadata filtering, which is still inefficient and expensive. It is possible that a weighted approach may play a bigger part in how we infer meaning from text, only time will tell.
See More Posts
Cardy
Copyright © 2021 Govest, Inc. All rights reserved.