What is Covariate Search?
Michelangiolo Mazzeschi • 2024-12-22
Introduction to covariate search, the new alternative to semantic search
Covariate Search
In this article I am going to explain the new search approach called covariate search (Michelangiolo Mazzeschi, 2024). While semantic search can only encode one element at a time, covariate search let us encode multiple elements in the same vector without losing information (set2vec). Covariate search is open-source on GitHub and is free to use.
What are the use cases of Covariate Search?
This approach is the latest breakthrough in the search field. As of now, we can only compare a pair of elements (one-to-one). With covariate search, we can now compare groups of elements together (many-to-many).
There are countless use cases where the data is not stored as raw text, but rather as sets of keywords, tags, labels (or other elements), common examples are:
- Retail products
- Resumes and HR data
- User profiles
Covariate search, when compared with semantic search on the same data, is much better (up to 70% better performance). With this new approach, we can finally retrieve data correctly, substantially improving retrieval results. To understand how covariate search works, let us compare it with the traditional semantic search and its limitations.
How does Semantic Search work?
Let us work on the following example. We have a database of resumes, and we would like to enable semantic search on top of them. The first step will be to encode each individual resume into a vector. More advance approaches may even split the resume into multiple sections and encode them indivudally, but for now we can keep it easy: one resume corresponds to one vector.
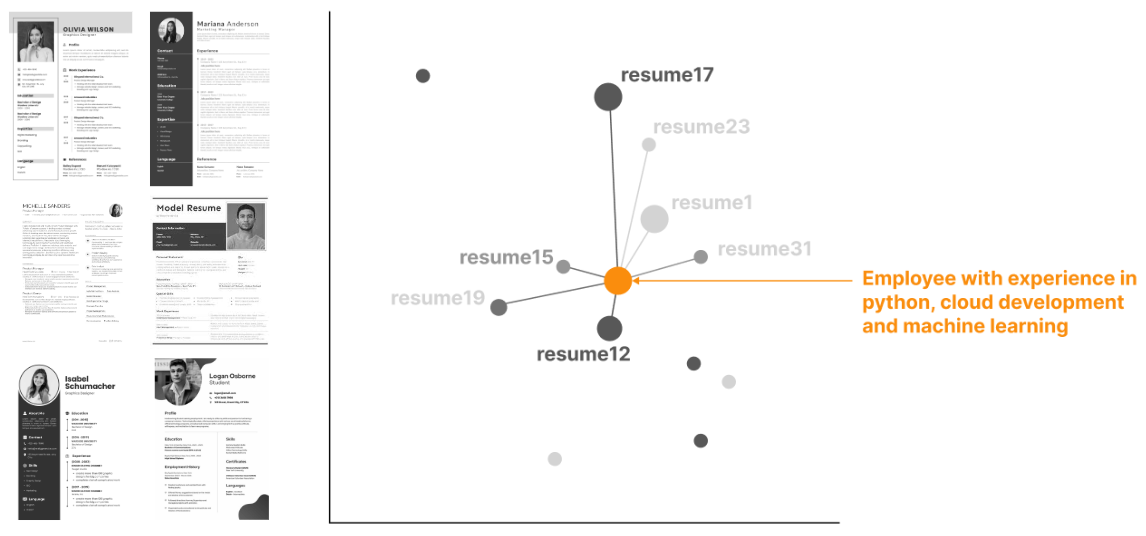
Can we encode multiple elements with semantic search?
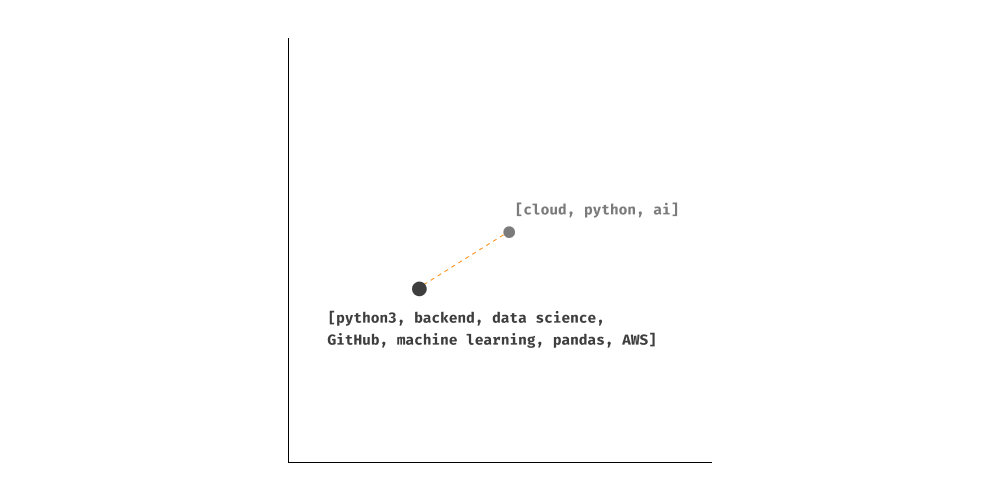
The limitations of semantic search become clear when we need to encode a set of elements in the latent space. In the example below, one resume is interpreted as a list of the following keywords:
By using traditional encoders, this is how the encoding will look like: one vector per keyword.
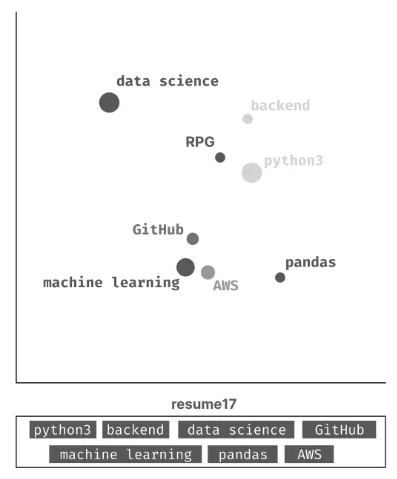
This becomes very challenging when we need to compare different resumes (different sets of keywords together). We can hardcode a solution, but there is no computationally or accurate wa of comparing set of different vectors together.
So far, the only viable solution to this problem would be averaging all keywords to obtain a single vector, as show below (or, for the data science practitioners, convert the list into a string for slightly better accuracy, despite the results are still very disappointing).

How does Covariate Search work?
The advantage of covariate search is the ability to encode a set of elements (several keywords, in the example above) into a single vector, mantaining its semantic properties.
1. one_hot Encoding
To do this, the first step is to create a set of all the keywords extracted from the dataset. We will be following the standard way of encoding a set of keywords, which is called one hot.

The big disadvantage of using one_hot for keyword search is that every keyword is encoded as a unique element. For example, python and python3 are not identical (they are only similar to our eyes, but not to a compute): the encoding process does not take into account any semantic relationship between keywords. My objective, with the next steps, will be to solve this limitation.
2. Dot Product
Prior to encoding any individual sample, we have prepared a matrix consisting of all the keywords encoded using a pre-trained encoder. The vector length of any sample processed by a standard encoder can vary (usually it range between 256 and 1024 dimensions). If the one_hot vector counts 500 total keywords, and the encoder generates vectors of length 384, we will need to encode each individual keyword to generate a matrix of 500x384.
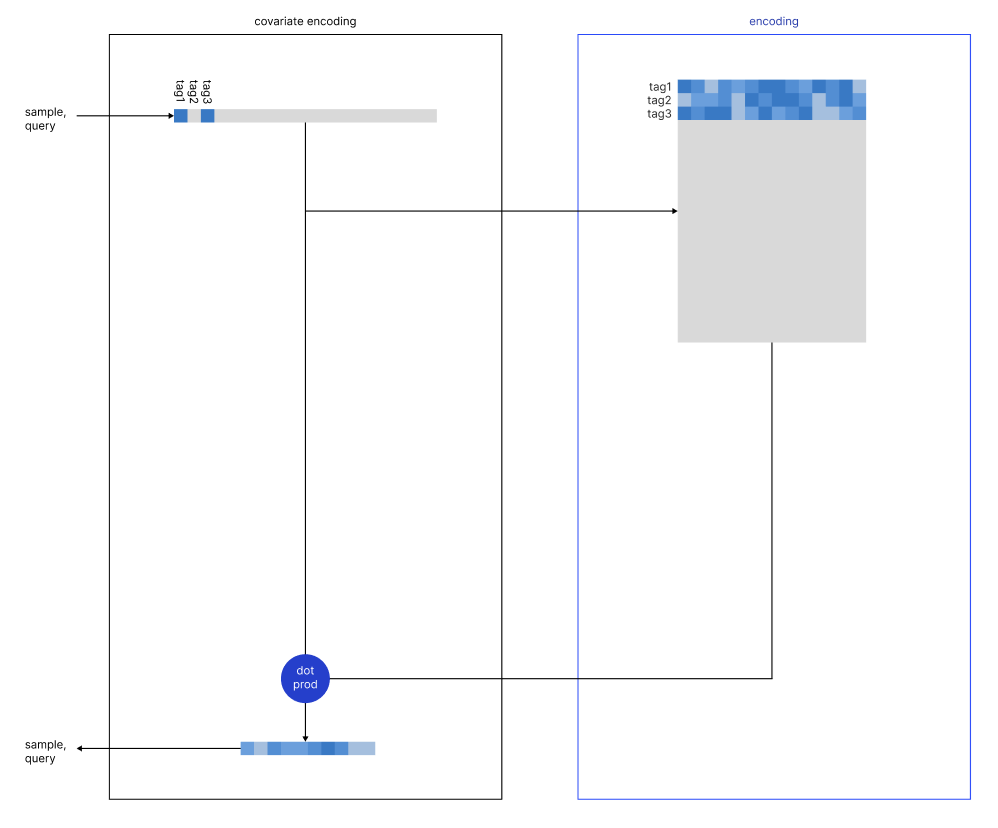
The encoding process is fairly simple: for any new set of keywords, we will first create the one_hot vector with the corresponding keywords and we will finalize the encoding by peforming a dot product between this vector and the relationship matrix.
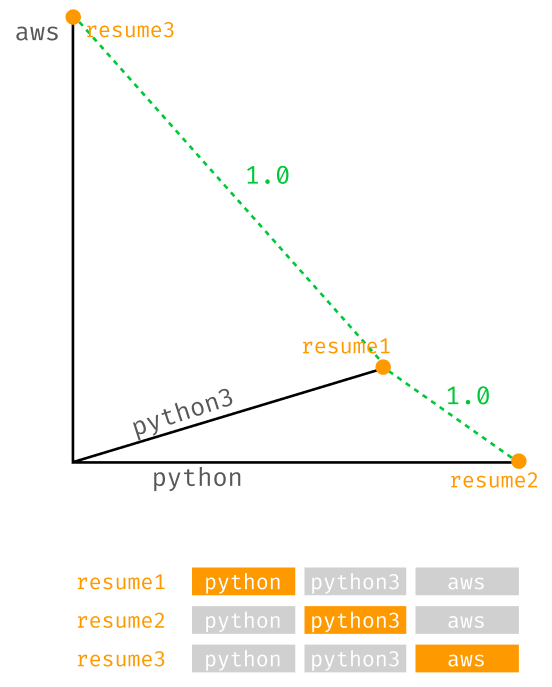
This process is able to apportion the relationships from the Matrix to the one_hot vector. The following example will make the explanation even clearer. Imagine to have a much smaller problem at hand, and have to have three possible keywords: [ python, python3, aws ].
This is how encoding three sets into regular one_hot will look like:
- resume1: [ python ] → [ 1, 0, 0 ]
- resume2: [ python3 ] → [ 0, 1, 0 ]
- resume3: [ aws ] → [ 0, 0, 1 ]
The distance between resume1 (python) and resume3 (aws) is 1. But also the distance between resume1 (python) and resume2 (python3) is also1. As explained, with regular one_hot the semantic relationship are not taken into account, therefore each keyword will be equally distant from another one, even if they are very similar.
Let us now look at how different the encoding process will be when using the dot product: the relationships contained in the Matrix have shifted the axis in a way to capture the semantic relationship of each respective keywords against all the others. Finally, let us check the relationship between the data points once again: The distance between resume1 (python) and resume3 (aws) is 0.8. However, the distance between resume1 (python) and resume2 (python3) is 0.3.
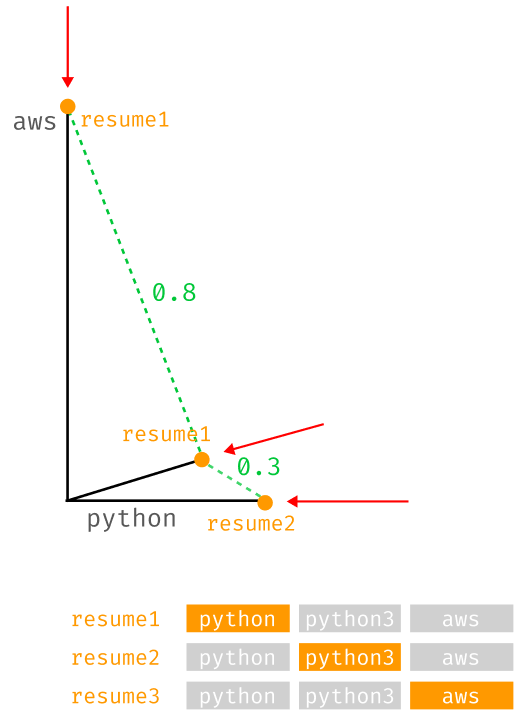
Finally, resume1 (python) and resume2 (python3), which contain almost semantically identical keywords, are considered to be similar. This example is limited to 3 dimensions for visualization purposes, but the same exact logic extends to multiple dimensions (or the total length of the one_hot vector).
3. Covariate Encoding
Now that we have clarified the entire process, we can finally apply covariate encoding to the set of keywords. Visualized, this is how one set is encoded into the latent space:

Now, we are able to compare different sets by taking into account their semantic properties, and we can do that by using cosine similarity as a similarity measure (considering both elements are now vectors).

As you can see, we have not resorted to any data cleaning or hardcoded any solution for to unlock semantic keyword search, but we have used a set of mathematical step to accomplish it.
Can we make Covariate Search scalable?
The biggest challenge of covariate search, in the absence of a neural network capable of emulating it, is scalabiliy. In the case of millions of keywords, the relationship matrix would become too big, and, by etension, the computing demand of the dot product.
We will explain in detail what are several ways of making covariate search scalable in other dedicated articles: consider that in one of our demos (which showcases covariate search on tech resume), we are using over 200.000 keywords, and the encoding process (as well as the retrieval) is as lighting fast.
Conclusion
This technology is a step up from the regular semantic search, and it shows how it is possible to extend the encoding of sets withot resorting to complex workarounds (which would require team of engineers cleaning the keywords and performing a detailed cluster analysis). This innovation has a long road ahead, but will be become one of the future pillars of data science and search.
See More Posts
Cardy
Copyright © 2021 Govest, Inc. All rights reserved.